基本信息
- 标题:Few-Shot Learning with Global Class Representations
- 年份:2019
- 期刊:ICCV
- 标签:global class representations, few-shot learning
- 数据:miniImageNet,Omniglot
创新点
- 通过在训练阶段引入新类的数据,同时对基类和新类学习全局类别表征,并利用样本生成策略解决类别不均衡问题,有效防止模型在基类数据中出现过拟合的现象,从而提高了模型泛化到新类的能力。
- 方法可以很容易的扩展到广义小样本学习(相比标准小样本学习,广义小样本学习中测试样本不仅包含新类,还包含了基类)。
- 所提的方法在标准小样本学习与广义小样本学习的benchmark上均取得了很好的效果。并且在广义小样本学习上,性能的提升更大。
创新点来源
首先,先了解几个知识点:
- 对于FSL问题,base classes每类均有足够的训练样本,而novel classes每类只有少量的标记样本。
- 现有的FSL方法都是基于元学习的。在元学习阶段,在base classes上采样来模拟Few-Shot Learning的条件。学习到的迁移知识通常以good initial conditions、embeddings、optimization strategies形式存储。元学习阶段之后,目标Few-Shot Learning问题通常有两种途径解决:一使用the learned
optimization strategy进行fine-tuning;二在不更新网络权重的情况下进行前向计算。
但是基于元学习的方法有一个根本性的问题:通常只使用基类数据训练模型(initial condition, embedding or optimization strategy),无法保证模型在目标数据上进行有效的泛化,即使在fine-tuning步骤之后。由于基类和新类之间存在严重的样本不均衡问题,导致容易过拟合到基类数据,这一点在广义小样本问题中尤为突出。通过在训练阶段引入新类的数据,同时对基类和新类学习全局类别表征,并利用样本生成策略解决类别不均衡问题,有效防止训练模型在基类数据中出现过拟合的现象,从而提高了模型泛化到新类的能力。
跟原型网络相比,本文主要有如下几个不同点:
- 本文学习的是全局类别表征,而不是episodic one;
- base class和novel class训练样本都用来学习表征。这保证学习到的类表征是具有全局一致性的,而不是local的;
- 本文引入了feature hallucination based方法,可以用来合成新的样本,解决类不平衡性问题。
主要内容
然而,这种全局类别表征最大的障碍是base与novel class训练样本之间的不均衡。作者使用了如下两种方式解决的这个问题:
- 通过合成数据增加novel class的类内多样性,通过在类样本子空间中随机抽样数据点,作者所提的合成样本策略可以有效地增加类内方差;
- 引入元训练去平衡base与novel class。具体来说就是representation registration,这部分内容比较复杂,在下面会详细展开。
Registration Module
假设样本集合为$C_{total}=\{c_1,\dots,c_N\}$,其中$N$表示类别总数。给定训练集集合$D_{train}$和测试集集合$D_{test}$,其中$D_{train}$的类别空间为$C_{total}$。registration module的主要作用为:将训练样本和全局类别表征进行比较,并选择出对应的全局类别表征。registration loss定义为全局表征和registration module的联合优化。下面进行具体介绍。
首先将训练集合中的一个训练样本$x_i$输入到特征提取器$F$中,获得其视觉特征,定义为$f_i=F(x_i)$。然后将该样本的视觉特征与全局类别特征表达$G=\{g_{c_j},c_i \in C_{total}\}$输入到registration module $R$中。对于每一个视觉特征$f_i$,registration module $R$都会产生一个向量$V_i=[v_i^{c_1},\cdots,v_i^{c_N}]^T$,其中第$j$个元素表示$f_i$与第$c_j$类全局类别表征$g_{c_j}$之间的相似性。在本文中,相似性得分的定义如下:

其中,$\theta(\cdot)$和$\phi(\cdot)$分别是样本视觉特征与全局类别表征的嵌入。
对于样本$x_i$(类别为$y_i$),定义registration loss $L_{reg}$,使得该样本与它对应的全局类别表征最接近,其中$CE$表示交叉熵损失:

通过将样本与所有全局类别表征($C_{total}$)进行比较,registration module使得每个全局类别表征接近其类内的样本,而远离类外的样本。值得注意的是,representation和特征提取网络都是可以端到端训练的,并且联合优化的。具体地说,利用训练好的全局类别表征,特征提取器被优化以将样本聚集在这些全局类表征周围;给定特征提取器,每个全局类别表征被优化为更接近同类样本而远离异类样本。
Sample Synthesis Module
为了解决novel classes样本过少引起的类别不平衡问题,本文提出了一个样本合成策略为novel classes合成样本。主要分为两个步骤:
使用原始样本产生新样本。具体来说,输入原始图像,使用随机裁剪、随机翻转和data hallucination策略合成样本。使用该方法后,每个novel class都可以获得总数为$k_t$的样本总数。
对于每一个新类$c_j$,首先从$k_t$个样本中随机选择出$k_r$个样本,从这$k_r$ 个特征$\{f_1,\cdots,f_{k_r}\}$组成的特征空间中,随机采样一个点合成一个样本。具体来说,在0~1均匀分布中采样出$k_r$个值$\{v_1,\cdots,v_{k_r}\}$;然后以这$k_r$ 个值作为权重对这些特征进行加权求和,得到了$c_j$类新的样本$r_{c_j}$,具体方程如下:
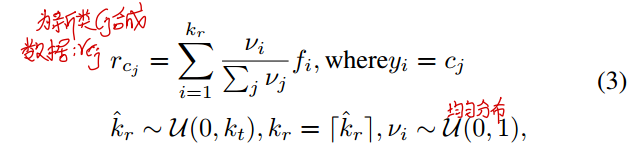
通过上述的策略,类内的样本多样性会增加,样本过少的问题也得到了减轻。上述这两个步骤可以概括为下面这副图:
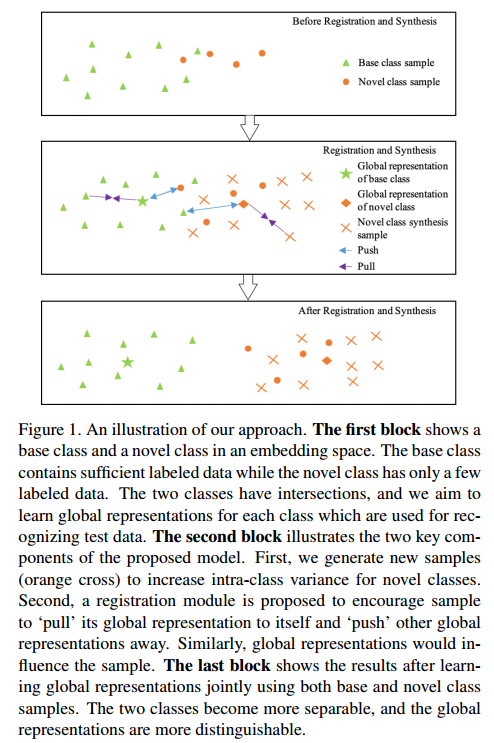
Few Shot Learning By Registration
除了上述的样本合成策略外,本文还使用了元训练策略。在FSL中,类标集合$C_{total}$分为两个不相交的子集$C_{base}$和$C_{novel}$。
在元训练阶段,首先从$C_{total}$个类别中抽取$n_{train}$个类别组成训练集合$C_{train}$;$C_{train}$每个类别均随机抽取$n_s$个样本组成支撑集$S=\{(x_i,y_i),i=1,2,\cdots,n_s\times n_{train}\}$;$C_{train}$每个类别随机抽取$n_q$个样本组成查询集$Q=\{(x_k,y_k),k=1,\cdots,n_q\times n_{train}\}$。值得注意的是,在训练集合中的novel class只有少量的$n_{few}$个样本,这通常远远少于$n_s+n_q$。所以,作者首先使用上一小节提到的数据合成的方法,合成$n_s+n_q$个样本,然后将他们划分为$n_s$和$n_q$,分别放到支撑集与查询集里面。
在元测试阶段,主要和元训练阶段有如下几个方面的不同:
- $C_{test}$仅由从novel classes中随机选择的$n_{test}$个类别组成;
- 使用这$n_{test}$个novel class在训练集合中的标记样本作为支撑集
- 查询集从$D_{test}$集合中选取,而不是$D_{train}$集合。
如果在元训练阶段,每个novel class有$n_{few}$的标记样本,那么FSL问题称为$n_{few}$-shot FSL;如果模型在测试阶段,从$n_{test}$的候选类别中预测结果,那么FSL问题称为$n_{test}$-way FSL。
接下来就开始进行整个FSL框架的描述。整个FSL框架示意图如下图所示:
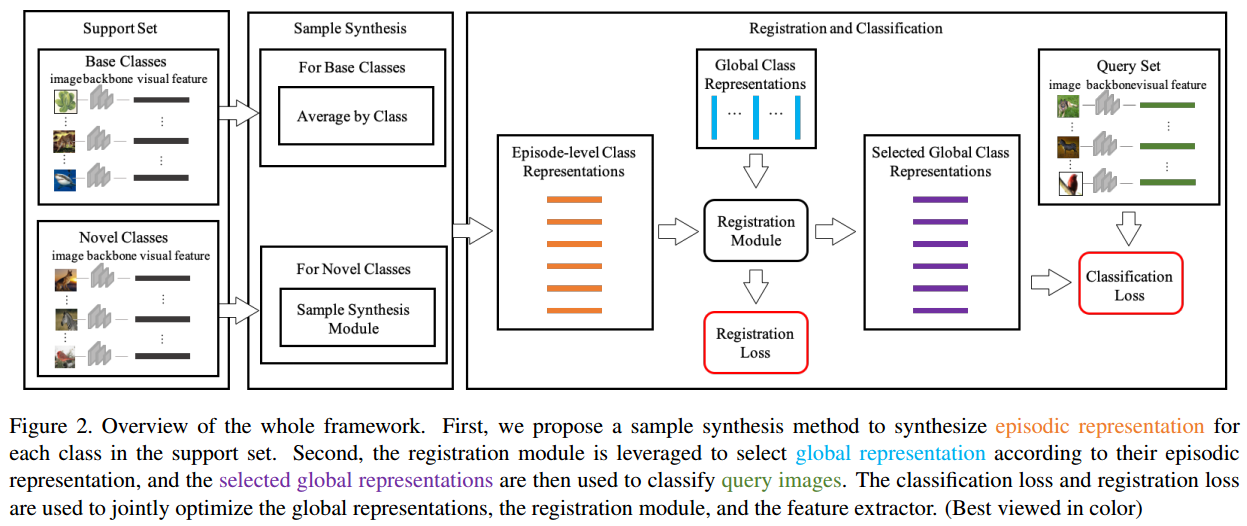
第一步,利用元学习策略将所提的样本合成模块加入到FSL框架中。也就是说,在每一次训练迭代过程中,支撑集$S$中的样本$S=\{x_i,i=1,2,\cdots,n_s\times n_{train}\}$首先被送入到特征提取器$F$中获得对应的视觉特征$\{f_i=F(x_i),i=1,\cdots,n_s \times n_{train}\}$。然后支撑集中的每一个类别建立episodic表征,记为$\{r_{c_i},c_i \in C_{train}\}$。该episodic表征$r_{c_i}$集成了当前mini-batch的支持集合$S$中的类$C_i$的信息;因此它是局部类别表征而不是全局类别表征。具体操作为:对于base classes,跟原型网络相似,平均同一类的视觉特征来获得episodic类别表征;对于novel class,将支撑集某类的特征作为输入,利用上述样本合成策略,为该类合成新的样本,从而得到的episodic novel类别表征更加多样化。
第二步,将registration module融入到FSL框架中,根据其episodic表征选择全局类别表征,选中的全局类别表征被用来对查询图片进行分类。特别的,将支撑集的episodic类别表征$\{r_{c_j},c_j \in C_{train} \}$和全局类别表征$G=\{g_{c_j},c_j \in C_{total}\}$输入到registration module $R$中,计算每一个episodic类别表征与全局类别表征之间的相似度,方程见上述方程1。
相似度得分被用来为查询数据集选择全局类标表征。为了使得全局类别表征更具有分离性,registration module定义了一个registration loss,使得episodic类别表征与对应类别全局类别表征之间的相似度得分更高。全局类别表征的分离性更强,识别未标记样本的能力越强。根据上面的方程2,每一个类别episodic表征$r_{c_i}$的registration损失定义如下:
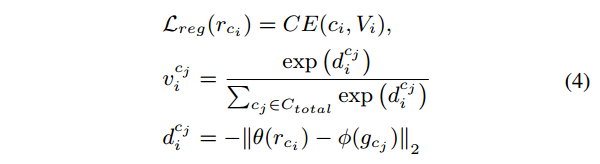
其中$V_i=[v_i^{c_1},\cdots,v_i^{c_N}]^T$表示$C_{train}$中类别$c_i$的episodic类别表征$r_{c_i}$与所有全局类别表征$\{g_{c_j},c_j\in C_{total}\}$的相似性得分。
第三步,利用得到的相似度得分,为$C_{train}$中的每一个类选择一个全局类别表征作为其类表征,并以选出的全局类别表征为参考进行最近邻搜索来识别查询图像。但是,当选择使用的是argmax操作时,它是不可微的。因此,以soft manner的形式选择类别表征。具体就是以概率分布$V_i$为权重,将所有类别的全局类标表征加权求和,得到$C_{train}$中第$i$类的类别表征$\varepsilon_i$,记做$\varepsilon_i=V_iG$。这样就获得了$C_{train}$中所有类别对应的全局类别特征$\{\varepsilon_i,i=1,\cdots,n_{train}\}$。查询样本$\{x_k,y_k \} \in Q$的分类损失定义如下:
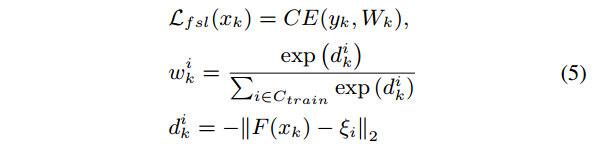
其中,$F$为特征提取模块,$W_k=[w_k^1,\cdots,w_k^{n_{train} }]^T$表示查询样本$x_k$与选中的全局类别表征$\varepsilon_i$之间的相似性。
将registration loss与分类损失结合到一块,就可以得到训练过程中的总损失函数,方程如下:
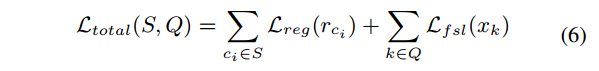
元训练的整个过程如下,值得注意的事项我均以下划线表示出来了。

在元测试集阶段,使用相同的流程去预测未标记样本的类标。也就是说,首先将支撑集输入到特征提取器中,得到每一个类别的episodic类别表征。然后,通过registration module与episodic类别表征得到对应的全局类别表征。然后,通过计算测试样本的特征向量与选出的全局类别表征之间的欧几里德距离来执行最近邻搜索。
Extension to Generalized FSL
虽然本文方法初始是用来设计标准FSL过程的,但是它能够很容易的扩展到广义FSL问题:唯一的区别在于测试样本同时从基类和新类抽取,预测时需要预测查询样本属于$C_{total}$个类别的类标。而标准FSL的测试数据只来源于novel classses。registration module不仅优化novel类别表征,还更新了base类别表征。通过将每个查询样本与base和novel的全局类标表征进行比较,registration module可以直接预测查询样本属于$C_{total}$中每个类的概率。
实验结果
本文的实验主要是在miniImageNet和Omniglot两个数据集上展开的。关于这两个数据集的说明这里就不详细展开了,可以看之前的文章。
实验细节
网络结构:特征提取器由四个残差block组成,每个block由64个$3 \times 3$卷积核、BN层、RELU激活函数和一个$2 \times 2$的最大池化层组成。registration module中的两个嵌入模块$\theta$和$\phi$均使用的是全连接层,全连接层的输出维度为512。
训练过程:首先,借助分类任务,使用所有的base classes训练特征提取器。然后,通过首先使用预先训练好的$F$其类中提取图像的视觉特征,然后对这些视觉特征进行平均来初始化每个全局类别表征。data hallucinator用预先训练的$F$作为特征提取器进行预训练。registration module采用的是高斯初始化,并从零开始训练。初始化特征提取器、全局类别表征、data hallucinator、registration module之后,将他们放到一块进行端到端的训练。
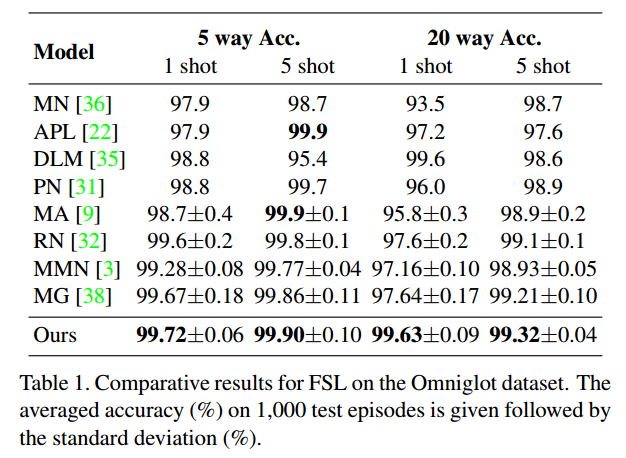
Results on Omniglot
5way 1-shot/5-shot,20way 1-shot/5-shot。其中,way表示测试集合中类别的个数,而shot表示每类支撑集的个数。不管是1-shot还是5-shot,每个类别均有五个查询样本。在元测试阶段,支持集中的图像是从训练集中随机选择的,而查询集中的图像是从测试集中随机选择的。可以观察到,本文的方法取得了新的最先进的性能。这验证了该方法的有效性,因为它采用了独特的全局类别表征学习策略。
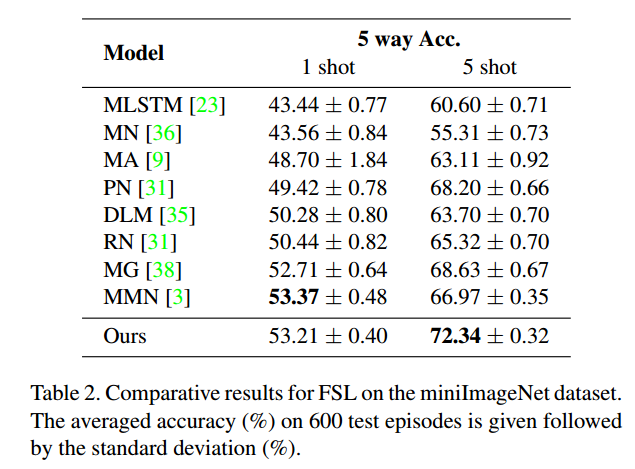
Results on miniImageNet
我们可以看到,我们的方法在5-way 5-shot设置上的性能明显优于其他FSL方案,并且在5-way 1-shot设置下达到了最好的效果。
Generalized Few-Shot Learning
使用的是miniImageNet数据集,类别划分方式相同(64//16/20),采用的新的数据划分方式,对于base classes,从600张图片中随机选择500张图片,novel classes中随机选取少量样本作为训练数据集。从剩下的数据中,每个base/novel类别,从中选取100张图片作为测试集。
定义广义FSL问题的评价指标为:
- $acc_a$:将所有类别的测试样本识别正确的概率
- $acc_b$:将base classes的测试样本识别正确的概率
- $accu_a$:将novel classes的测试样本识别正确的概率
值得注意的是,计算上述指标的时候,均需要将测试样本映射到$C_{total}$的标记空间。
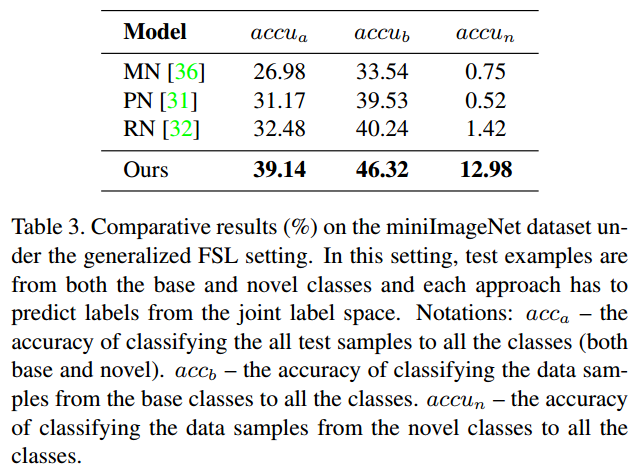
实验结果如上表所示,可以观察到:
- 本文的方法在所有的评价指标上都取得了最好的结果,比标准设置下的结果有更大的差距。这表明在这种更具挑战性的环境下,本文的模型具有最强的泛化能力。
- 本文方法优于PN和RN,因为这里学习每个类的全局类别表征,而它们估计episodic类别表征。
- MN的结果比本文的方法低得多。
总结
本文首先分析基于元学习的方法有一个根本性的问题:通常只使用基类数据训练模型(initial condition, embedding or optimization strategy),无法保证模型在目标数据上进行有效的泛化,即使在fine-tuning步骤之后。由于基类和新类之间存在严重的样本不均衡问题,导致容易过拟合到基类数据,这一点在广义小样本问题中尤为突出。
针对这个根本性问题,作者通过在训练阶段引入新类的数据,同时对基类和新类学习全局类别表征,并利用样本生成策略解决类别不均衡问题,有效防止训练模型在基类数据中出现过拟合的现象,从而提高了模型泛化到新类的能力。
本文值得借鉴的地方是episodic类别表征与全局类别表征之间的关系是通过registration module进行的。也就是每次会使用registration module模块,对每个episodic类别特征与所有全局类标表征做相似性度量,选择出该类别对应的全局类标特征。然后由选出的全局类标特征与查询样本进行比较,得到查询样本的类标。不过,关于样本扩充的方式不太适用于非图像领域。

